
type
status
date
slug
summary
tags
category
icon
password
反刍系列,即对他人输出内容的理解
把那些匆忙剪藏的内容拿出来再嚼吧两下,或许能品尝到不同滋味
1. 1 什么是 stable diffusion?
图片 AI 生成技术,重点在于 diffusion(扩散)

1.1. 1.1 Diffusion 发展历史
名称 | 时间 | 意义 | 通俗解释 |
DDPM | 2020.6 | 一切从这里开始 | 最早的扩散模型:像“照片还原术”,从模糊变清晰,AI 开始学会“反着修图”来生成图像。 |
DDIM | 2020.10 | 提升效率 | 是 DDPM 的加速版,流程简化很多,生成速度更快但效果不差。 |
Classifier Guidance | 2021.5 | 控制能力提升(打败 GAN) | 加了“内容纠察员”帮助 AI 判断画得对不对,比如你说“猫”,它确保不会画出狗。 |
Classifier-Free Guidance | 2021.7 | 又快又可控 | 不需要分类器也能做到精准控制,让 AI“自我纠偏”,速度还更快。 |
GLIDE | 2021.12 | 奇迹诞生的开始 | AI 终于能画出复杂又逼真的图了,有点像“学会艺术的 AI”。 |
Latent Diffusion | 2021.12 | 大幅提高效率 | 先把图片压缩处理再还原,节省大量算力,好比“先画草图再上色”。 |
LAION 5 B | 2022.3 | 数据基础 | 喂给 AI 50 亿张图+说明,相当于“看遍全世界”,理解和想象力大大增强。 |
DALLE-2 | 2022.4 | 使用 unCLIP 技术 | 更懂语言、更会画画,能根据很复杂的描述创作高质量图像。 |
Stable Diffusion | 2022.8 | 爆炸性成果 | 快、开源、效果好、人人可用,真正把 AI 画图带到大众生活中。 |
2. 2 技术原理
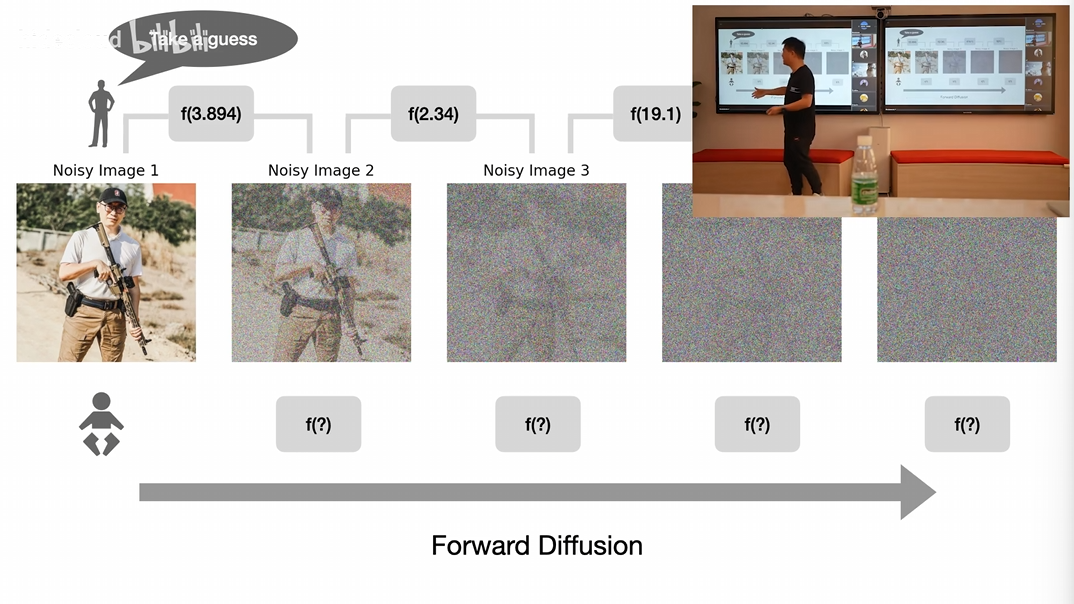
2.1. 2.1 正向扩散
- 原始有张清晰的图
- 不断加随机噪点,直到符合高斯分布
- 注意:随机不是纯随机,而是有一个噪点函数;正向扩散过程就是符合高斯分布(即正态分布,最常见的概念分布),最终完全得不出原来图片的信息
2.2. 2.2 模型训练过程
- 假定从一张图从原图到模糊需要 1000 步
- 先设定好一个噪点函数,人为准备好每一步需要传入噪点函数的值
- 让模型来根据变化后的图片,猜测每一步输入噪点函数的值是多少
- 最终达成效果:模型看到一张图,能猜出传入噪点函数的值是多少
2.3. 2.3 逆向扩散(使用过程)
- 模型在训练过程中,不是记住了一张图片该如何还原(即特定的图形分布),而是学会了如何去除噪点(图形本质的规律)
- 在没有文本的情况下,图片会随机从噪点变成具体图片,但和训练数据还是有很强的关联性,例如人脸训练集随机生成的图片大概率就是一张人脸,这种叫无条件扩散模型(Unconditional Diffusion)
- 在有文本的情况下,会靠近文本的引导,生成具体的图片,但还是会很大程度受训练集的影响

3. 3 扩散模型的面临的问题
3.1. 3.1 图片的复杂性
- 每一张图片可以分为三个渠道,红,绿,蓝
- 每个渠道都有一个矩阵,导致计算量十分庞大
3.1.1. 3.1.1 解决方案:VAE 技术
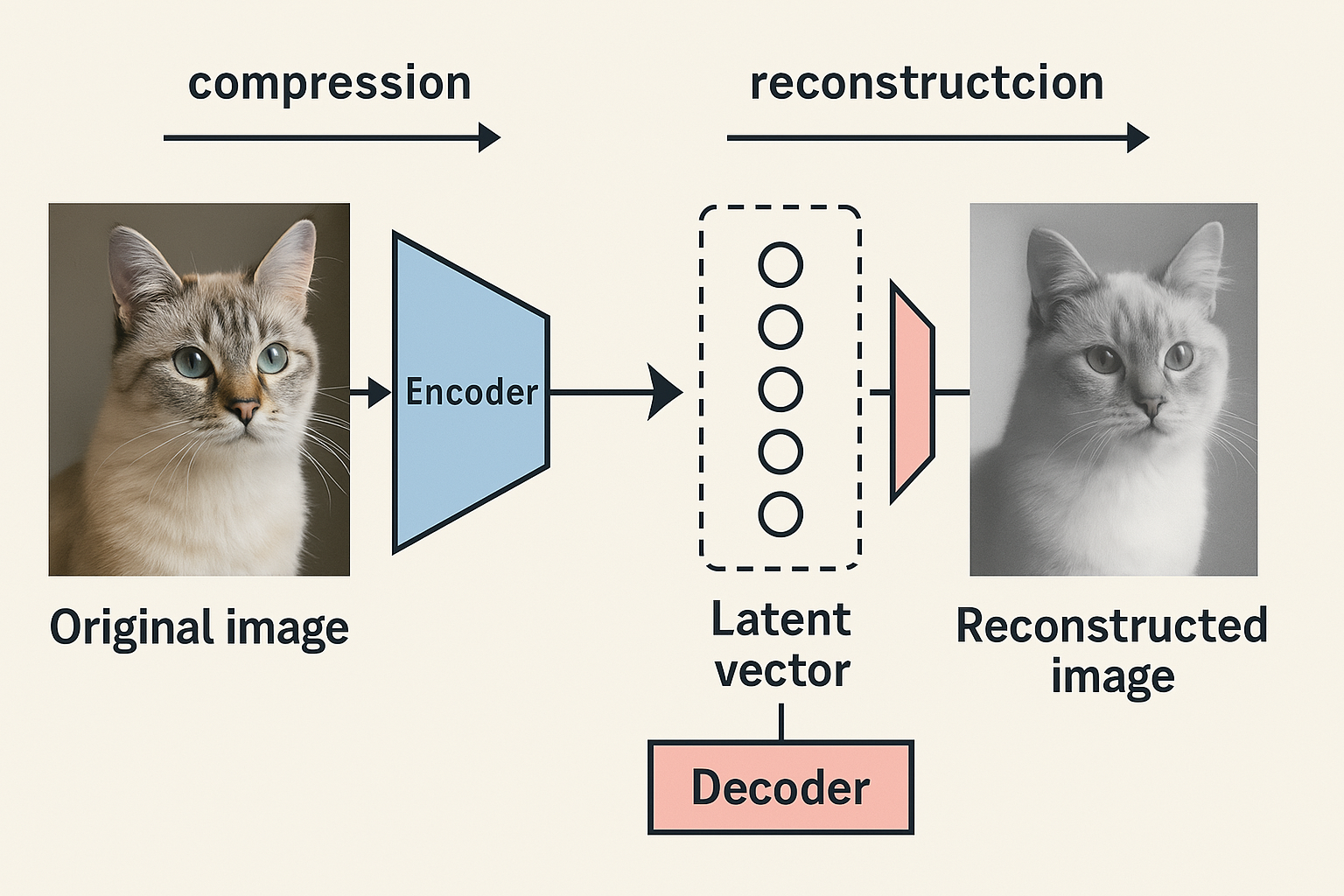
- VAE 是一种可以“学会如何压缩和还原图像”的神经网络结构,由一个编码器(压缩)和一个解码器(还原)组成。
- 编码器会把原始图片转换成一个叫做“潜空间向量”的数字摘要,就像用关键词总结一张图。
- 解码器则根据这个摘要尽可能地还原出原图,整个过程是经过大量训练反复优化的。
- VAE 在训练时会比较原图和还原图的差距(叫“重构损失”),同时还用 KL 散度保持生成结果的稳定性和多样性。
- 它的作用是让 AI 在一个更小、更简单的空间里处理图像任务,大大提高效率,并保证生成图像的质量和一致性。
3.1.2. 3.1.2 为什么 VAE 可以编码再解码,其中不会损害图像吗?
- 不会,vae 本质上是在提取图片的特征,例如猫咪图片,会提取毛发,圆脸,有耳朵等等,保存特征的情况下,可以压缩数据的同时还能复原出来
- 需要注意:上述特征只是举例,VAE 提取的特征可能不是人可以理解的文本,而是一些向量或者数学表达,这也是 AI 领域中的黑盒问题
3.2. 3.2 如何控制图片生成?
如上文所述,如果放任模型自由从噪点变成图片,那么就是仿照训练集生成一张图片,业务价值不高
如何让扩散模型能够被人类控制是一个很大的问题
3.2.1. 3.2.1 文本控制-训练过程
3.2.2. 3.2.1.1 目标:
训练模型学会“如何根据文字从噪声中生成图像”。
3.2.3. 3.2.1.2 步骤说明:
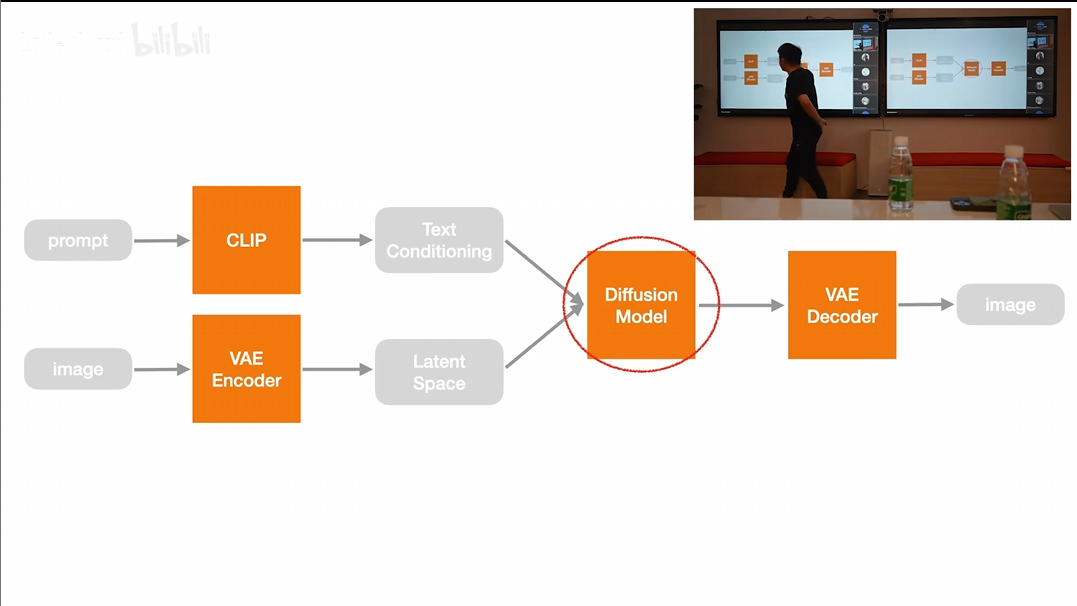
- 文本编码(Text Encoding) 使用 CLIP 文本编码器,将一段文字(prompt)转为向量,表示它的语义。这些向量会在后续生成图像时提供指导。
- 图像编码(VAE 编码器) 把真实图片输入 VAE 编码器,将图像压缩成简化的潜空间表示。这个压缩形式保留了图像的核心特征,便于后续处理。
- 加噪声(Forward Process) 在压缩后的图像上逐步添加噪声,使其变模糊。这样可以让模型学习“从模糊到清晰”的过程。
- 去噪训练(U-Net) 使用 U-Net 网络,输入“被加噪的图像”和“文字向量”,训练模型一步步把图恢复成清晰的潜空间图像。注意,这里是预测噪声,而不是预测图像,也就是学习绘图能力,而不是单纯的记住图像。
- 目标 模型的任务是尽可能“去掉多余的噪声”,还原成最接近原图的样子。每次还原不够好,模型会自动修正,逐渐学会如何准确生成。
3.2.4. 3.2.2 文本控制-推理过程
3.2.5. 3.2.2.1 目标
给定一段文字,生成一张新的图像。
3.2.6. 3.2.2.2 步骤说明
- 文本编码 使用 CLIP 文本编码器,将用户输入的描述文字转为向量,表示其含义。
- 初始化随机图像(潜空间) 从纯噪声开始生成图像(不再需要原始图片)。
- 逐步去噪(U-Net + Text Condition) 使用训练好的 U-Net 网络,根据文字的语义信息,一步步将噪声图“变清晰”,直到生成完整的潜空间图像表示。
- 图像还原(VAE 解码器) 使用 VAE 解码器,将最终得到的潜空间图像还原为清晰的彩色图像输出。
3.2.7. 3.2.3 主要术语解释
术语 | 作用说明 |
CLIP 文本编码器 | 把文本转换成模型可理解的向量,用于控制图像内容。 |
VAE 编码器/解码器 | 将图像压缩成潜空间表示(编码)和将其还原为图像(解码)。 |
U-Net | 生成模块,负责一步步将噪声图像还原成目标图像。 |
Cross-Attention | 在图像生成过程中注入文本信息,让模型理解“你想画什么”。 |
潜空间(Latent Space) | 压缩后的图像表示,用来提升处理效率并减少资源消耗。 |
3.3. 3.3 图生图解释
从文生图可以类比过来,图生图本质上就是把文本向量引导改成了图片向量引导,其他步骤基本一致
3.3.1. 3.3.1 关键参数 denoise strength
如果想要文+图生成图片,有个关键参数就是 denoise strength,0-1 区间,越高越偏向文本,越低越偏向图片
4. 4 实际运用
- Stable diffusion 是一个底层模型,需要用代码调用,上手难度高
- 有两个 UI 界面,一个是配置形式,一个是 workflow 形式
- 新手/用户界面推荐配置形式,pm 等需要个人调试的推荐 workflow 形式
至此,difussion 的基础原理基本解释清楚,后续就是在此基础上做的大量优化工作
5. 5 控制优化

图像生成过程中,Conditioning(条件控制)是提升生成质量与一致性的关键,下文介绍了几种控制模式
5.1. 5.1 ControlNet
一个用于扩散模型的结构控制框架,允许引入图像结构线索(如边缘、姿态、深度)来指导生成过程。
5.1.1. 5.1.1 • canny / scribble
- Canny:使用边缘检测结果作为结构提示。
- Scribble:用户手绘线条草图,作为创作参考。
- 📌 用途:构图辅助,快速草图转图像。
5.1.2. 5.1.2 • depth
- 基于输入图生成深度图(depth map),再用作条件引导。
- 📌 用途:增强空间感、透视和三维结构的表达。
5.1.3. 5.1.3 • openpose
- 使用 OpenPose 提取人体关键点(骨架)作为结构条件。
- 📌 用途:精确控制人物动作和姿势。
5.1.4. 5.1.4 • IPAdapter
- 使用图像作为参考,引导生成图的风格或内容。
- 📌 用途:图像风格迁移、形象一致性控制。
5.2. 5.2 • inpaint / outpaint
- Inpaint:局部修改/填补图像区域。
- Outpaint:扩展图像边界内容,生成“画外”的图像。
- 📌 用途:图像编辑、修复、画面扩展。
5.3. 5.3 • Photomaker / InstantID
- 输入照片,驱动生成与人像风格一致的新图。
- 📌 用途:基于真实人脸生成多风格图像,实现一致的人设或角色。
6. 6 生成速度&成本优化
6.1. 6.1 LCM
6.1.1. 6.1.1 定义
LCM 是一种用于 快速生成图像的扩散模型替代方案,它的目标是将原本需要十几步(如 20 步)才能完成的生成流程,压缩到 2~4 步以内完成,极大提升速度,同时保持不错的质量。
6.1.2. 6.1.2 原理简述
在传统的 Stable Diffusion 里:
- 你从随机噪声出发,经过 20~50 步去噪(Diffusion steps)才得到最终图像。
- 每一步都是渐进式优化图像质量,代价是速度慢。 LCM 的做法是:
- 它用一种类似 蒸馏(distillation) 的方法,在潜空间里训练一个模型,直接预测出最终图像的大致方向。
- 这样可以 跳过很多中间步骤,达到“直达终点”的效果。
6.1.3. 6.1.3 LCM 的优势
特点 | 说明 |
极快 | 只需要 2~4 步即可生成图像 |
兼容潜空间 | 直接在 VAE 潜空间中工作,和 SD 模型结构一致 |
轻量部署 | 更适合用于低延迟场景,如移动端、互动应用、实时生成 |
问题:需要在每个模型中进行蒸馏,普及成本高
6.2. 6.2 LCM LoRA 是什么?
LCM LoRA 是将 LCM 的加速能力以 LoRA 形式打包 的版本,用户可以将其 加载到已有的 Stable Diffusion 模型上,快速获得 LCM 的效果。
6.2.1. 6.2.1 LoRA 简单说明:
- LoRA(Low-Rank Adaptation) 是一种轻量模型微调技术。
- 它可以只训练模型中少量的参数,保持原模型不变,适用于灵活加载/合并。
- 常用于个性化模型、风格模型扩展,现在也用于功能性增强(比如 LCM、ControlNet 等)。
6.2.2. 6.2.2 LCM LoRA 的作用
特点 | 说明 |
无需换模型 | 原 Stable Diffusion 模型不动,只加载 LoRA 文件即可 |
轻量集成 | 文件体积小(一般几十 MB),加载快,部署方便 |
立即加速 | 一旦加载,就能让生成速度显著提升(如从 20 步降到 4 步) |
6.3. 6.3 总结
名称 | 类型 | 功能 | 使用方式 |
LCM | 模型结构/方法 | 快速图像生成(极大减少生成步骤) | 作为新模型训练或整合 |
LCM LoRA | 微调模块(插件) | 把 LCM 的能力“插入”原模型中 | 加载到原 SD 模型即可使用 |
6.4. 6.4 业务价值
- 成本和速度得到了极大的提升,意味着可以做实时变化了,这就改变了商业模式,从异步变成了同步
- 由此字节推出了儿童涂鸦产品,一边修改,一边生成,一个很精准的切入点:
- 儿童的耐心不强,娱乐属性,十分重视及时反馈
- 儿童对画作的要求质量不高,尤其是涂鸦转化后的画作,能很简单带来 aha 时刻
- 父母的付费意愿强,能快速看到孩子画作的优化结果,情绪价值拉满,叠加教育属性,很容易收费
7. 7 DIT-质量优化
DiT 是 Diffusion Transformer 的缩写,是一种将 Transformer 架构引入扩散模型(Diffusion Model) 的新型生成模型结构。
通俗地说,它是把图像生成领域从用 CNN(如 U-Net)为主的传统架构,升级为 Transformer 架构的一种尝试和趋势。
7.1. 7.1 前置概念-cnn
CNN 是专门为处理图像而设计的神经网络,擅长识别图像中的局部结构,比如边缘、颜色块、纹理等。
7.1.1. 7.1.1 工作原理
将图像看作一个像素网格(比如 256 x 256 像素)
用“小窗口”扫描整张图,提取局部特征(比如眼睛、轮廓)
每一层都提取更高层次的结构(从边缘 → 五官 → 整张脸)
7.1.2. 7.1.2 优点
高效处理图像局部信息
计算速度快,结构简单
在图像分类、识别中表现优秀
7.1.3. 7.1.3 局限
不擅长建模“长距离信息”或图像整体结构
控制能力弱(不容易融合复杂条件信息)
7.2. 7.2 前置概念-transformer
Transformer 是一种基于“注意力机制”的神经网络,最初用于语言处理(如翻译、对话),现在广泛应用于图像、音频、多模态任务中。
7.2.1. 7.2.1 工作原理
输入被拆成一系列“片段”(图像块或词)
每个片段都可以“注意”其他所有片段,通过权重决定谁重要
模型自动学习全局结构,理解整体上下文
7.2.2. 7.2.2 优点
擅长处理全局依赖(长距离信息)
易于加入额外控制条件(如文本、姿态、风格)
支持多模态(图文结合、视频处理)
7.2.3. 7.2.3 局限
参数多,计算量大
对小数据集训练不如 CNN 稳定
7.3. 7.3 前置概念-注意力机制
注意力机制的本质:模型在处理一个元素时,不是只看它自己,而是会“权衡”其他所有元素的信息,决定该关注谁、关注多少。这就像人看一段文字时会结合上下文去理解一个词的含义,而不是孤立地看一个词
7.3.1. 7.3.1 工作原理
在 Transformer 中,注意力机制是一种让每个词/图像块都可以动态地从其他位置获取有用信息的方式。它通过比较“我需要什么”(Query)和“别人能提供什么”(Key)来决定“我该从谁那里学”。
7.3.2. 7.3.2 核心组成
组件 | 含义 | 功能 |
Query (Q) | 查询向量 | 表示当前元素在“找什么” |
Key (K) | 键向量 | 表示每个元素“能提供什么” |
Value (V) | 值向量 | 是每个元素“真正提供的信息内容” |
7.3.3. 7.3.3 工作流程
- Q 和所有 K 做对比 → 得到“注意力权重”(谁重要)
- 对所有 V 加权平均 → 得到融合信息后的新向量
- 每个位置的输出都带有“全局上下文”的信息
7.3.4. 7.3.4 比喻总结:
你可以把注意力机制看作一个“智能会议系统”:
- 每个成员写好“我想听什么”(Q),
- 也告诉别人“我能讲什么”(K),
- 然后根据匹配结果去听别人讲的内容(V),综合成自己的新理解。
7.4. 7.4 为什么要用 Transformer 做扩散模型?
7.4.1. 7.4.1 传统方式:Stable Diffusion 使用 U-Net
- U-Net 是基于卷积神经网络(CNN)的结构,适合局部图像建模。
- 它对图像细节很敏感,但对长距离关系、复杂控制较弱。
7.4.2. 7.4.2 DiT 的变化
- 使用的是 Vision Transformer(ViT) 结构。
- 它将图像切成 patch(小块),像处理语言一样处理图像,用 自注意力机制 来理解图像整体结构和细节。
- 天然支持全局建模、复杂条件控制(如风格、位置、动作等)。
7.5. 7.5 DiT 的核心优势
特性 | 说明 |
全局建模能力强 | Transformer 擅长理解长距离依赖,图像结构更合理。 |
更强的条件控制能力 | 更容易嵌入文字、布局、风格等多种引导信息。 |
更适合大模型训练 | 支持高效并行计算,适合大规模训练,易扩展到视频、4 K 图像等。 |
已在多个任务中超越 U-Net | 如高分辨率图像生成、图文匹配、视频生成等领域效果显著。 |
7.6. 7.6 应用场景和代表模型
- OpenAI Sora:其背后技术很可能就用了类似 DiT 架构来处理视频的时空信息。
- 高质量图像生成:DiT 生成的图片在细节一致性、全局结构上普遍优于传统方法。
- 多模态控制:如图像 + 文本 + 深度图多条件输入时,Transformer 更容易融合这些信息。
7.7. 7.7 和 U-Net 的对比简表
维度 | U-Net(CNN) | DiT(Transformer) |
架构类型 | 卷积神经网络 | 自注意力 Transformer |
特点 | 本地建模强 | 全局建模强 |
控制能力 | 一般 | 强,适合复杂任务 |
可扩展性 | 一般 | 强,适合视频/高分辨率 |
适用模型 | Stable Diffusion v 1/v 2 | DiT, Sora, SDXL-like 架构 |
8. 8 轻量级优化-TAESD
8.1. 8.1 一句话简介
TAESD 是一个可以在边缘设备上运行、生成速度极快、同时保持较好图像质量的轻量级文生图模型。
8.2. 8.2 TAESD 是什么?
TAESD 全称是:Text-Aligned Efficient Stable Diffusion,
由 Stability AI 团队发布,目标是构建一个能在**资源有限设备(如手机、嵌入式系统)**上运行的高效图像生成器。
它是 Stable Diffusion 架构的一个轻量替代版本,专门针对部署、性能、低功耗进行了优化。
8.3. 8.3 解决了什么问题?
问题 | 原始 Stable Diffusion | TAESD 改进点 |
模型大 | 原模型 > 4 GB | 模型小至 100 MB 级别 |
推理慢 | 需要几十步才能生成 | 推理可在 1 步完成 |
难以移动部署 | 需 GPU + 大内存 | 可部署在手机/浏览器/边缘设备上 |
8.4. 8.4 核心特点
特性 | 说明 |
超快生成 | 可实现 1-step 推理(1 步生成图像) |
轻量模型 | 体积约 150 MB,远小于原始 SD 模型 |
精度对齐文本 | 输出图像仍与文本有较强对应关系 |
蒸馏模型 | 利用大模型训练出来的小模型,保留质量的同时压缩体积 |
可部署性强 | 支持 Web、移动端、嵌入式环境 |
8.5. 8.5 技术机制简述
TAESD 背后的主要思想是:
使用 蒸馏(Distillation) 技术,将原始 SD 的复杂去噪过程压缩成一步,同时保留语义对齐能力。
- 它会“学习”完整 Stable Diffusion 模型的行为
- 并用一个简单网络快速“模仿”整个去噪过程
- 训练时用的是 text-aligned latent pairs(文本-潜空间对齐) 数据
8.6. 8.6 适用场景
应用场景 | 意义 |
移动端 AI 创作 | 实时生成图片、头像、壁纸 |
浏览器端运行 | Web APP 中直接运行 AI 绘图 |
低功耗硬件 | 如树莓派、AR/VR 眼镜等轻型设备 |
快速预览 | 用 TAESD 预览草图,再交给 SD 高清重绘 |
8.7. 8.7 与 Stable Diffusion 的关系
项目 | TAESD | Stable Diffusion |
模型大小 | 小(~150 MB) | 大(>4 GB) |
步骤数 | 1(单步) | 20+(多步) |
输出质量 | 较好,但略逊色 | 更高清、可控性强 |
运行设备 | 轻量设备、浏览器 | 高配 GPU |
8.8. 8.8 总结
TAESD 是一款为“快速推理”和“移动部署”优化的 Stable Diffusion 轻量版本,适合追求生成速度和低资源消耗的场景。
它是 Stable Diffusion 技术普及化、边缘智能化的关键一步。
9. 9 文本优化-Better clip
Better CLIP 并不是一个正式的模型名称,而是对原始 CLIP 的增强版本或替代实现的统称,常见的有:
- OpenCLIP(由 LAION 社区训练)
- SigLIP / EVA-CLIP / CLIPA / CoCa 等其他研究组织发布的升级版 这些版本通常具备更大的训练数据、更强的模型结构、更好的文本理解能力,并广泛应用于图像生成、图文检索、多模态理解等任务。
9.1. 9.1 核心差异对比(CLIP vs Better CLIP)
对比项 | CLIP(原始版本) | Better CLIP(如 OpenCLIP) |
来源 | OpenAI(2021) | 开源社区或研究组织 |
训练数据 | 4 亿图文对 | 多达 10~50 亿图文对(如 LAION 5 B) |
模型结构 | ViT-B/32、RN 50 | ViT-H/14、ViT-G/14 等更强结构 |
文本理解 | 英文为主 | 多语言支持,文本理解更深 |
表现能力 | 良好 | 精度更高,更稳健 |
开源可用性 | 限制多,非商业许可 | 完全开源,可商用部署 |
10. 10 思考
10.1. 10.1 艺术是否消亡了
- 人类创造的内容在整个概率空间是十分稀疏的
- AI 本质上还是学习人类,然后进行一定的概率扩散,从本质上来说还是围绕人类之前创作的内容进行改造
- 艺术风控的模仿是 AI 最为擅长的事情,创新很难;联想到最近到 gpt,吉普力风格的模仿就是一个典型案例
10.2. 10.2 多读 paper(keep reading)
- AI 发展趋势太快了,多读 paper 能够带来极大的信息差
- 信息差可以带来更高的视野,预测未来发展,提前做好布局
10.3. 10.3 一定要自己上手
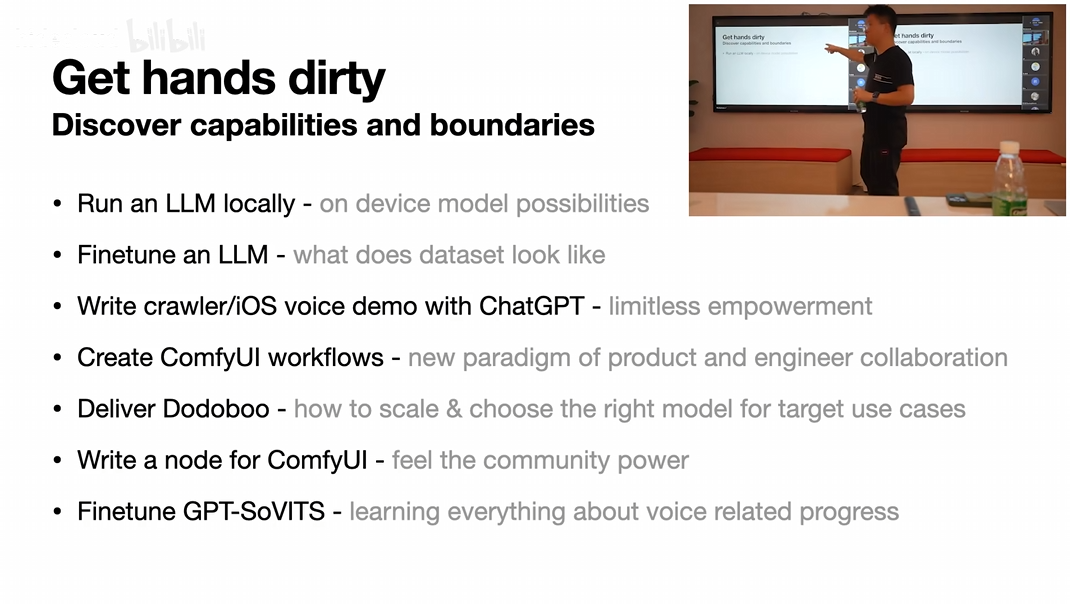
- 强大的模型不一定是最合适的模型,自己的动手才知道最合适自己 case 的是什么
- 亲身体验模型的能力才能激发思考,延伸未来的工作场景
- 重点在于:发现模型的能力和边界,对未来的预测性
- Author:培风
- URL:http://preview.tangly1024.com/article/1cea80cd-73cf-80ad-a1ae-f965250e3be7
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!











