
type
status
date
slug
summary
tags
category
icon
password
1 什么是推理模型
1.1 模型需要 token 来思考
传统模型中,我们会使用 cot 的形式,来强制模型一步一步思考
推理模型就是讲 cot 内嵌到基座模型中,每个问题都会先输出思考内容,再输出结论

1.2 和传统 COT 有什么区别?
传统 COT 需要人来前置确定,告诉你如何一步一步思考,最终达成【模型输出思考内容】的效果
推理模型自己就会先【一步一步思考】,最终提升输出效果
即:思考是手段而非目的
此外,依赖人来告诉你如何思考,上限是用户
模型自主能思考,才能突破人的上限,达成真正的智能
2 R1 的复现历程
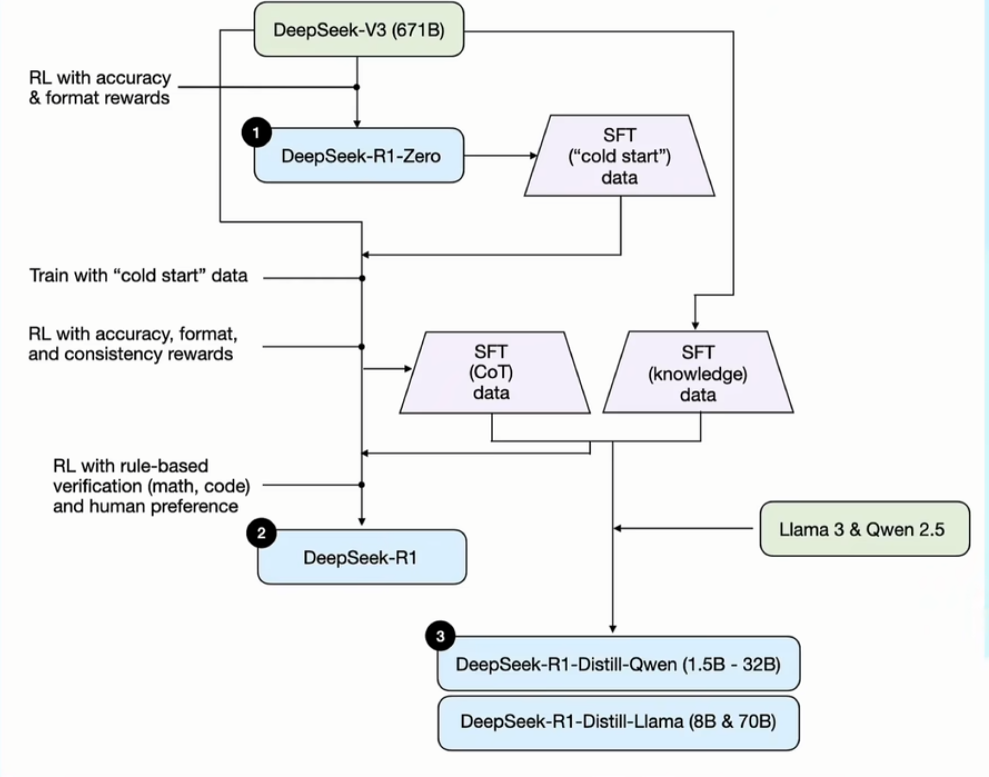
2.1 V 3 到 R 1 Zero
基于 V 3(传统基座大模型)进行训练,训练模板如下,其中 prompt 为各类题目
两个激励函数:
- 准确度激励:是否答对
- 格式激励:是否带有 think 和 answer 标签
搁置问题:为了快速训练模型,DS 采用了 GRPO 的激励训练方式,那么为什么会采用这种方式呢?和传统 PPO 有什么差别呢?
模型在上面两个激励函数的作用下,模型自主发现:
思考越长,越容易答对

小结:
- V 3 是 DS 自主研发的基座大模型
- 在 V 3 基础上,DS 进行了激励训练,工具是:一个提示词模板+两个激励函数
- 训练完成后,R 1 自己发现了思考越多,准确度越高,并且能力确实得到了提升
2.2 R 1 Zero 进化为 R 1
- 先用 R 1-Zero 生成一批带有思考过程的数据集,然后用这个数据集来微调 V 3模型
- 针对微调后的 V 3 模型,再次进行了激励训练,这次除了激励准确度和格式外,还增加了语言一致性的维度,保证输出内容使用同一个语种
- 激励训练后的 V 3 模型,生成了一批高质量的 COT 数据,再用 V 3 生成了一批通用的数据集,用这两个数据集再次进行了训练,最终得出了 R 1
3 其他工作
3.1 训练其他大模型
- 在得到高质量的思维链数据和基础知识数据后,DS 团队还能这个数据集训练了其他公司的基座模型(llama 3 和 qwen 2.5)
- 整体表现比原生模型会更好,进而证明:推理是一个增益性 buff,并且所有人都可以做到
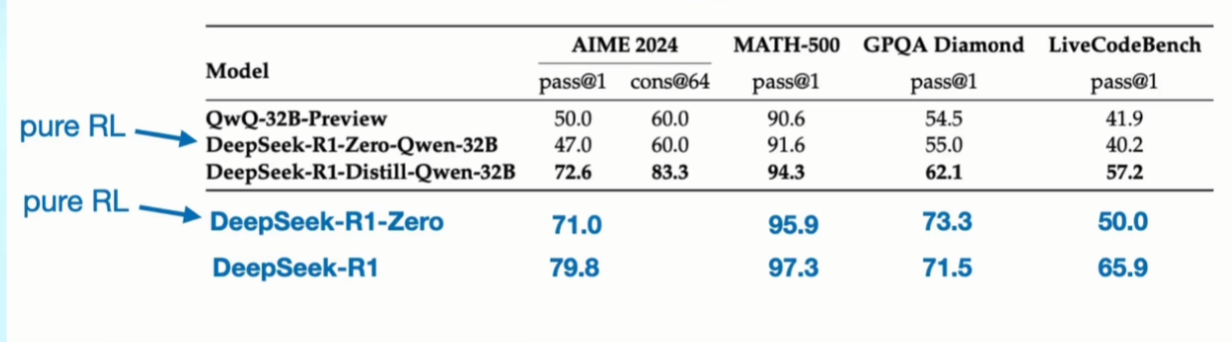
3.2 尝试下限
使用小尺寸模型,走一遍训练流程,发现实际效果并没有表现更好,由此可以得出两点:
- 推理本身也是模型能力的一部分,R 1 只是挖掘了模型的潜力,无法提升上限
- V 3 大模型就是扎实的内功,DS 在 AI 的长期积累,才能从 V 3 推出 R 1
- Author:培风
- URL:http://preview.tangly1024.com/article/1bca80cd-73cf-80e5-8ac3-f740293c34b3
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!










